Convolutional Neural Networks (CNNs) are a type of deep learning architecture specifically designed for processing grid-like data, such as images. Their ability to learn complex features and extract spatial information has made them the dominant architecture for various computer vision tasks.
1. Understanding the Building Blocks of CNNs:
- Convolutional Layers: The core building block of a CNN, consisting of filters that slide over the input image and compute dot products with local regions of the image. These filters learn to detect specific features, like edges, lines, and textures.
- Pooling Layers: Downsample the input by summarizing the information within local regions. This reduces the dimensionality of the data and helps to control overfitting. Common pooling strategies include max pooling and average pooling.
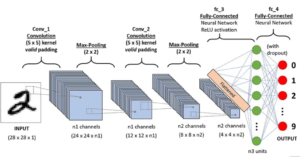

- Activation Functions: Introduce non-linearity to the network, allowing it to learn complex patterns. Popular activation functions for CNNs include ReLU and Leaky ReLU.
- Fully Connected Layers: Similar to traditional neural networks, these layers receive flattened outputs from the convolutional layers and perform classifications or regressions.
2. Learning and Optimization in CNNs:
- Gradient Descent: An iterative algorithm that updates the weights of the network based on the gradient of the loss function. This process helps the network minimize the loss and improve its accuracy.
- Backpropagation: Computes the gradient of the loss function with respect to the weights of the network, enabling efficient updates during training.
- Momentum: Accumulates gradients over iterations, providing a “push” in the right direction and accelerating learning.
- Adaptive Learning Rates: Adjust the learning rate dynamically based on the gradient’s magnitude, preventing large swings in the parameter updates and improving stability.
3. Advanced Architectures and Techniques:
- Residual Networks (ResNets): Introduce skip connections that directly connect layers, allowing the network to learn long-range dependencies and improve performance.
- Inception Networks: Employ multiple parallel convolutional filters with different kernel sizes to capture features at different scales.

- Batch Normalization: Standardizes the inputs to each layer, accelerating training and improving stability.
4. Applications of CNNs:
- Image Recognition: Identifying objects, scenes, and activities in images.
- Object Detection: Localizing and recognizing objects in images.
- Image Segmentation: Segmenting an image into different regions corresponding to different objects or categories.
- Medical Image Analysis: Detecting diseases and abnormalities in medical images.
- Self-Driving Cars: Recognizing objects and navigating in road environments.
5. Conclusion:
CNNs have revolutionized the field of computer vision due to their ability to learn complex features and achieve remarkable performance on various tasks. With their ongoing development and increasing computational power, CNNs are poised to drive further advancements in computer vision and related fields.